xcerpting
from
the title page of
Puzzles
with a Purpose, "Our purpose is to
celebrate processes and principles..."
This puzzle gives us an
opportunity to illustrate
practical methods used in making predictions --
predictions with incomplete
information, in fact. Well, let's be careful with
the word "fact,"
taking into account a principle expressed in The
Future is Not What it Used to Be... xcerpting
from
the title page of
Puzzles
with a Purpose, "Our purpose is to
celebrate processes and principles..."
This puzzle gives us an
opportunity to illustrate
practical methods used in making predictions --
predictions with incomplete
information, in fact. Well, let's be careful with
the word "fact,"
taking into account a principle expressed in The
Future is Not What it Used to Be...
"For I repeat: there are no
'facts' about the
future. Only 'opinions'."
Which is not to say, there are no facts at
all. Football
has its rules, and each team has its records.
However, in The
Next Superbowl puzzle, the identities of
the teams are not yet
known.
Information about the future is just
about always incomplete
-- worse: inaccurate or wrong, biased or
misleading. Unless more
and better information can be obtained -- make that until
more and
better information can be obtained -- you must work
with what you have.
Superbowl Sunday is coming, which is a metaphor for
many kinds of
management decisions that won't wait for all the
desired information to
materialize.
A recommedation repeated often on these
pages is invoked
again here with an excerpt from Discovering
Assumptions,...
"Discovery is nourished by
assumptions. If you
don't have enough data, you what? -- assume something.
When there is too
much of the stuff or it's riddled with contradictions,
what else can you
do? Assume something."
"But!" bellowed the instructor while
commencing an exaggerated
scrawl across the top of the blackboard: "Make your
assumptions explicit!"
 ere
goes... ere
goes...
Assumption #1
That
the objective of each team will be to maximize its
own score independently
at all times. Some assumptions are easy to
make. This one simplifies
our analysis by setting aside tactical matters arising
on the field resulting
from relative scores. A team in the lead will
act the same as a team
coming from behind.
Assumption #2
That
the next Superbowl will not end with a shut-out.
Teams in the Superbowl
are the best in the league; you would not expect
either to be held scoreless.
It is a good idea to make explicit why each assumption
is being made. This
one avoids a bias toward the digit zero for a losing
team that scores less
than 10. The next two assumptions are intended
to simplify our analysis...
Assumption #3
That
there will be no safeties and no two-point
conversions in the next Superbowl.
Knowledge does play a part in assumptions such as this
one. Though
not impossible, both of these scoring increments are
extremely rare, as
anyone familiar with the game will know.
Assumption #4
That
there will be no missed conversions in the next
Superbowl. Missed
conversions are indeed rare, but, more relevantly,
they are irrelevant,
since the same scoring effect will result from any
pair of field goals,
which are not rare.
At
this point we have
developed the beginnings of a model for the next
Superbowl. A model?
 ur
assumptions lead us to expect that at every scoring
opportunity, each team,
whoever they are, will most likely score either seven
points (a touchdown
followed by a successful conversion) or three points (a
field goal). Many
unknowns will influence those decisions as the teams
interact with each
other. ur
assumptions lead us to expect that at every scoring
opportunity, each team,
whoever they are, will most likely score either seven
points (a touchdown
followed by a successful conversion) or three points (a
field goal). Many
unknowns will influence those decisions as the teams
interact with each
other.
Time out. Whereas
touchdowns are
often scored in a sequence of offensive plays
following a kickoff return,
touchdowns can also result from a turn-over
(pass-interception or fumble)
anywhere on the field. Field goals, on the other
hand, can be scored
only by the team in possession of the ball -- the
offensive team -- and
only from some limited distance from the goal line.
Assumption #5 That,
out
of every three successful scoring opportunities, a
team will make two
touchdowns and one field goal. Before
continuing here, you may
want to explore "The Price of a
Point."
This assumption merely appropriates the results from the
solution to that
puzzle.
 he
first Superbowl was played in Los Angeles between the
Green Bay Packers
of the NFL and the Kansas City Chiefs of the AFL on
Sunday, January 15,
1967. As of this writing there have been a total
of 36 Superbowl
Sundays. In solving The
Next Superbowl
puzzle,
surely you will want to consult the records from all
previous games.
Not so fast... he
first Superbowl was played in Los Angeles between the
Green Bay Packers
of the NFL and the Kansas City Chiefs of the AFL on
Sunday, January 15,
1967. As of this writing there have been a total
of 36 Superbowl
Sundays. In solving The
Next Superbowl
puzzle,
surely you will want to consult the records from all
previous games.
Not so fast...
For what purpose might all
that information be
used?
Well, you say, it is relevant
knowledge, isn't it?
Plenty of facts, in fact.
On the other hand, what we really
want to do here is formulate
a model that will predict events for which we have
limited knowledge and
no facts at all. Unlike the weather and other
trendy phenomena suitable
for extrapolation, least significant digits in
football scores are, from
game to game, utterly independent.
A football pool is much like a casino game
in which the winner
is determined by a wheel with numbered frets, each
corresponding to a square
in the payoff matrix. As we have already noted,
however, those frets
are not all equally spaced.
The best use of those Superbowl
records, it seems plain,
will be to test the validity of our assumptions, the
quality of our reasoning
-- hey, the predictive power of our model.
We are not predicting the past, so we
dare not be influenced
by events from the past that have no causal connection
to the next Superbowl.
Accordingly we elect to defer consultation of the
record-books until after
we make all of our assumptions and develop the
model. We can always
use that information later to adjust our
assumptions. The technical
term is "tweaking."
For now, let us pretend it is
 s
a game played against the clock, football necessarily
imposes an upper
limit on the scores for both teams. Only so many
touchdowns and field
goals can take place in the time allowed. The
total depends on the
offensive and defensive strengths enjoyed by both teams
taken together.
Taken separately, those same qualities determine the
closeness of the contest. s
a game played against the clock, football necessarily
imposes an upper
limit on the scores for both teams. Only so many
touchdowns and field
goals can take place in the time allowed. The
total depends on the
offensive and defensive strengths enjoyed by both teams
taken together.
Taken separately, those same qualities determine the
closeness of the contest.
Relative score is the sine
qua non for making
wagering decisions. For a football pool, the absolute
scores
decide the winning squares in the payoff matrix, for
we saw earlier that,
under our assumptions, certain digits are unlikely to
appear in football,
especially in low scores, whatever the score of the
other team.
Here are two numerical
assumptions derived by
-- well, derived by SWAG. The acronym stands for
"Stupid Wild-Ass
Guess." You cannot get more explicit than that.
Assumption #6 That
the
total score accumulated by both teams in the next
Superbowl will be
no more than 45 points.
Assumption #7
That
the winning team will outscore the losing team by a
margin of 2-to-1.
 ou
will recall that the puzzle gave us another clue ("the
team in
is
favored to win"). Upsets are not infrequent,
though, so what we have
here is not so much a clue as an additional puzzle
condition.
Instead of being given the names of the teams before
the next Superbowl,
we are told that the winner's name
will be assigned to the matrix for the columns and the
loser's name
will be assigned to the rows (after the game is over,
obviously). ou
will recall that the puzzle gave us another clue ("the
team in
is
favored to win"). Upsets are not infrequent,
though, so what we have
here is not so much a clue as an additional puzzle
condition.
Instead of being given the names of the teams before
the next Superbowl,
we are told that the winner's name
will be assigned to the matrix for the columns and the
loser's name
will be assigned to the rows (after the game is over,
obviously).
The SWAGs in Assumptions #6 and #7 have
the winner scoring
no more than 30 points maximum and the loser scoring
no more than 15 points.
The losing team, for example, might score anywhere
between 3 and 15 (a
shut-out having been precluded by Assumption
#2). The winning team,
under our assumption, can accumulate up to 30 points,
so long as its final
score is higher than that of the losing team when the
clock runs out.
Throughout the
game both teams are
afforded what we have been calling "scoring
opportunities" at which, if
successful, points are accumulated. Each successful
scoring opportunity
could be the last one in the game; accordingly, the
next Superbowl can
be represented as a set of successful scoring
opportunities. Indeed,
any number of "next Superbowls" can be thus
simulated. Forget about
other statistics (running and passing, interceptions
and fumbles).
But in the next Superbowl, how many
points, 7 or 3, will
be accumulated at each successful scoring
opportunity? Nobody knows,
of course. When the range of numerical values
for an unknown is known
but nothing else, people often resort to a random
process and rely on what
is popularly known as The Law of
Averages.
Assumption #8
That
the scoring increments accumulated by a team at each
successful scoring
opportunity can be selected by a random
element. In effect, we
can flip a three-sided coin... Excuse the interruption
-- "three-sided
coin"? Sure. Think of a cylinder whose
diameter equals its
height. Around the periphery is printed the
phrase "field goal,"
and the two faces each read "touchdown." Neat,
huh.
One of the most
practical tools
for modeling nowadays is the spreadsheet (see, for
example, Easy
as Pi). The author has created a Spreadsheet
Model for Solving the Next Superbowl Puzzle.
ere
are
the results from a thousand Superbowls.
|
LSD
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
Winner %
|
9.0
|
1.4
|
11.4
|
16.6
|
|
3.4
|
36.2
|
|
2.4
|
19.8
|
|
Loser %
|
20.4
|
|
0.2
|
19.0
|
23.2
|
|
4.0
|
33.0
|
|
0.2
|
Each of these percentages represents
the likelihood --
the chance -- of the respective cypher appearing as
the least significant
digit in the final score. A blank entry means
that under our assumptions,
the corresponding cypher will appear so infrequently
in the next Superbowl
that they have been dropped from consideration
(columns
4
and
7,
along with rows 1,
5,
and 8).
Taken as products of percentages in all
possible combinations,
these numbers represent the joint likelihood of
winning $100 in each of
the corresponding squares. Any product less than
1.0% means we can
discard that combination as being less likely than one
in a hundred (pure
chance).
Your best choice, apparently,
is 6-to-7,
which will appear in final scores of 16-7, 26-7, or
26-17. The chance
of that outcome is given as the product of 36.2% *
33.0% = 12.0%, which
is 12 times more likely than "luck of the draw."
The next best is
6-to-4,
which will appear in final scores of 16-14 or 26-14
and enjoys a likelihood
more than 8 times what uniformly distributed cyphers
would imply.
Indeed, there are 22 squares worth betting
on, as shown in
the following tabulation:
Winner
Digit
|
Loser
Digit
|
Joint
Chance %
|
Total
Wager
|
Cumulative
Chance %
|
|
6
|
7 |
11.9 |
1 |
11.9 |
|
6
|
4 |
8.5 |
2 |
20.3 |
|
6
|
0 |
7.4 |
3 |
27.7 |
|
6
|
3 |
6.9 |
4 |
34.6 |
|
9
|
7 |
6.5 |
5 |
41.1 |
| 3 |
7 |
5.5 |
6 |
46.6 |
| 9 |
4 |
4.6 |
7 |
51.2 |
| 9 |
0 |
4.0 |
8 |
55.2 |
| 3 |
4 |
3.9 |
9 |
59.1 |
| 2 |
7 |
3.8 |
10 |
62.9 |
| 9 |
3 |
3.8 |
11 |
66.7 |
| 3 |
0 |
3.4 |
12 |
70.1 |
| 3 |
3 |
3.2 |
13 |
73.3 |
| 0 |
7 |
3.0 |
14 |
76.3 |
| 2 |
4 |
2.7 |
15 |
78.9 |
| 2 |
0 |
2.3 |
16 |
81.2 |
| 2 |
3 |
2.2 |
17 |
83.4 |
| 0 |
4 |
2.1 |
18 |
85.5 |
| 0 |
0 |
1.8 |
19 |
87.3 |
| 0 |
3 |
1.7 |
20 |
89.0 |
| 6 |
6 |
1.4 |
21 |
90.4 |
| 5 |
7 |
1.1 |
22 |
91.5 |
The payoff matrix for the football pool
may now be marked
to show the Order of Preference for each of your
wagers...
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
0
|
19 |
|
16 |
12 |
|
|
3 |
|
|
8 |
|
1
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
3
|
20 |
|
17 |
13 |
|
|
4 |
|
|
11 |
|
4
|
18 |
|
15 |
9 |
|
|
2 |
|
|
7 |
|
5
|
|
|
|
|
|
|
|
|
|
|
|
6
|
|
|
|
|
|
|
21 |
|
|
|
|
7
|
14 |
|
10 |
6 |
|
22 |
1 |
|
|
5 |
|
8
|
|
|
|
|
|
|
|
|
|
|
|
9
|
|
|
|
|
|
|
|
|
|
|
By the way, this is
the solution to
The
Next Superbowl puzzle. Well, one
solution, anyway.
As a matter of more than idle
curiosity, you
will want to check the validity of our assumptions
against Superbowl records.
Have fun (see History of
the Superbowl).
ere
is
the payoff matrix with all 36 past Superbowls
superimposed.
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
0
|
19 |
|
16 |
12 |
|
|
3 |
|
|
8 |
|
1
|
|
|
|
|
|
|
|
|
|
|
|
2
|
18 |
|
|
|
|
|
|
|
|
|
|
3
|
20 |
|
17 |
13 |
|
|
4 |
|
|
11 |
|
4
|
|
|
15 |
9 |
|
|
2 |
|
|
7 |
|
5
|
|
|
|
|
|
|
|
|
|
|
|
6
|
|
|
|
|
|
|
21 |
|
|
|
|
7
|
14 |
|
10 |
6 |
|
22 |
1 |
|
|
5 |
|
8
|
|
|
|
|
|
|
|
|
|
|
|
9
|
|
|
|
|
|
|
|
|
|
|
A few observations...
-
Your selections would have paid off up
to 12 times, depending
on how many of those particular squares you
purchased year after year.
Exclamatory punctuation is advisable.
-
As indicated by the darker squares, five
winning combinations were duplicated
and one combination
(4-to-7)
appeared
in the final scores of three Superbowls.
You would have missed them all. Bummer.
-
The most recent
Superbowl (XXXVI) ended
with a score of 20-to-17 (0-to-7
in
the least significant digit department), and you
would have won -- but
only if you had purchased at least 14 of your 22
preferred squares.
Still, that was 7 times better than chance
odds. Hey, get a load
of this...
-
That 0-to-7
combination
in the final score of Superbowl XXXVI had never
appeared throughout the
history of the Superbowl. Even with access
to the records for all
35 games, you would be clueless. Not only
that, but...
-
If, for the
Superbowl XXXVI pool, you
had purchased the squares for all the combinations
that had ever appeared
in the past, it would have cost you $28 to find
out that the recordbooks
were no help to you. So much for
extrapolation, huh?
-
Finally, if,
year after year, you purchased
the squares for every combination that had
appeared in all previous years,
you would have wagered a total of $554 and won six
times, for a total of
$600. That's barely better than an even bet
(1-to-1 odds).
Our model would have done better. How much
better?
The table below shows the payoffs achieved
by applying the
solution to The Next
Superbowl
puzzle retrospectively in football pools for all
36 past Superbowls.
Have a look...
|
Superbowl
|
Year
|
Score
|
Preference
|
Wagered
|
Won
|
|
III
|
1969
|
16-7
|
1
|
$ 36
|
$ 100
|
|
XX
|
1986
|
46-10
|
3
|
108
|
200
|
|
V
|
1971
|
16-13
|
4
|
144
|
300
|
|
IV
|
1970
|
23-7
|
6
|
216
|
400
|
|
XXI
|
1987
|
39-20
|
8
|
288
|
500
|
|
II
|
1968
|
33-14
|
9
|
324
|
600
|
|
XXVII
|
1993
|
52-17
|
10
|
360
|
700
|
|
XXXVI
|
2002
|
20-17
|
14
|
504
|
800
|
|
XI
|
1977
|
32-14
|
15
|
540
|
900
|
|
XXII
|
1988
|
42-10
|
16
|
576
|
1,000
|
|
XXVIII
|
1994
|
30-13
|
19
|
684
|
1,100
|
|
IX
|
1975
|
16-6
|
21
|
756
|
1,200
|
|
N/A
|
N/A
|
N/A
|
22
|
792
|
1,200
|
This tabulation postulates 13
suppositions -- that you
purchased the indicated squares for $1 each, summing
up to the indicated
number of squares as determined by entries in the
column marked "Preferences."
Kind of a mouthful. See if these comments
help...
-
If you had bet a buck a year on just
your favorite square
(6-to-7),
you would have won only once (Superbowl III in
1969), losing ever since.
Overall, you got $100 in return for $36 in wagers
(almost 3-to-1 in Las
Vegas lingo).
-
If, starting back in 1967, you had
purchased your first three
preferences every year (6-to-7,
6-to-4,
6-to-0),
you would have won twice (Superbowls III and XX),
pocketing $200 for $108
in wagers. That's not great, but 2-to-1 is a
whole lot better than
chance (3 in a hundred).
-
Careful inspection of the table shows
that, provided you
put at risk $16 per year over 21 years (1967-1988),
you would have won
8 times, receiving $800, for a cost of $336 (almost
5-to-2 odds).
If you don't quit in 1988 (uh, why would you?) but
continue purchasing
the same 16 squares, by 2002 you would have invested
$576 and won $1,000
(better than 3-to-2).
-
Finally, you will see in the table
that by repeatedly purchasing
all 22 "Preferred" squares in the solution to The
Next Superbowl puzzle, you would have
won a total of $1,200
on $792 in wagers (still 3-to-2 odds) -- this,
despite the fact that Preference
number 22 (5-to-7)
never came up. Maybe next year.
s
expressed above, "The best use of those Superbowl
records...will be to
test the validity of our assumptions, the quality of
our reasoning -- hey,
the predictive power of our model." Inspection
of box scores in the
official Superbowl
records shows the following:
Assumption #1 Teams
maximize scores independently
-- confirmed as postulated, with the come-from-behind
team taking slightly
more risk (see Assumption #3).
Assumption #2 No shut-outs --
confirmed.
Assumption #3 No safeties and no
2-point conversions
-- a total 1,615 points have been scored throughout
the history of the
Superbowl; fewer than 14 have come from safeties and
2-point conversion
(respectively 5 and 2 of each, less than 1%.
Assumption #4 No missed
conversions -- the record
shows a 95.8% success rate.
Assumptions #5 Two-to-one
touchdowns versus field goals
-- a total of 192 touchdowns have been scored in
Superbowls and 97 field
goals. Would you believe 1.979-to-1?
Hoo-hah!
Assumptions #6 and #7 Those
danged SWAGS -- they
are the most doubtful. We want to examine them
closely in the light
of the historical records. Meanwhile...
Assumption #8 Use of random
element -- although
our model applied retrospectively did seem to give
quite satisfactory results,
we must not fail to notice that half a dozen
combinations of least significant
digits appeared repeatedly over the years, and our
model did not select
any of them.
he
SWAGs in Assumptions #6 and #7 imposed an arbitrary lid
on the teams of
15 and 30 points. Have you looked at those game
records? Some
tweaking music, please.
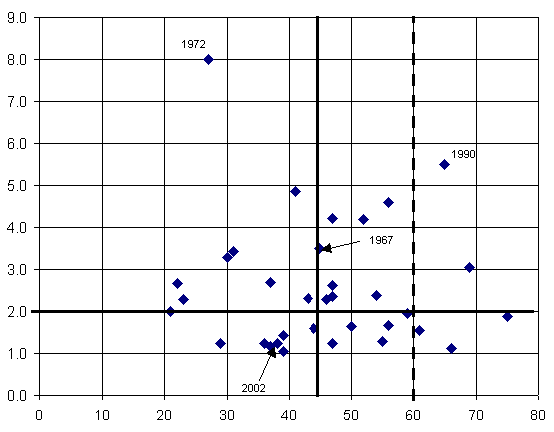
Superbowl
History: Ratio vs Total
Score
This scattergram depicts the historical
record of all
36 Superbowls. The total score for each game is
plotted on the horizontal
axis, and the ratio of the winning team's score to the
losing team's score
is plotted on the vertical axis. It looks like
it might have been
produced by an ink-sneeze, doesn't it.
-
The SWAG in Assumption #6 is
emphasized as a vertical line,
setting an upper limit on the total scores for
modeling purposes at 45
points. Clearly that does not comport well
with the historical record,
since half the games scored higher than 45
points. How embarrassing.
Exclamation point declined. The vertical dashed line
tweaks Assumption
#8, allowing the model to encompass all but 5 of the
games in history.
-
The SWAG in Assumption #7 is
emphasized as a horizontal line,
imposing a 2.0-to-1 ratio on the final scores.
Not too bad.
The average ratio is found to be 2.1 for all 36
games. By merely
eliminating those two humiliating routs that
occurred in 1972 (ratio 8.0-to-1)
and 1990 (ratio 5.5-to-1), the historical average
would indeed come out
2.0 on the nose.
-
In our model, the effects of tweaking
Assumption #6 are as
follows: Increase the upper boundary for the winning
team from 30 to 60
points and 15 to 30 for the losing team.
ere
are
the results from another thousand Superbowls.
|
LSD
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
Winner %
|
11.2
|
12.2
|
3.8
|
12.0
|
12.2
|
4.0
|
4.0
|
14.7
|
13.3
|
12.8
|
|
Loser %
|
20.3
|
7.7
|
0.2
|
8.6
|
21.3
|
|
3.8
|
32.2
|
3.8
|
2.1
|
Having tweaked Assumption #6,
we see that higher
scores mean more opportunies for each cypher.
This time, there are
28 squares worth betting on, as shown in the following
tabulation:
Winner
Digit
|
Loser
Digit
|
Joint
Chance %
|
Total
Wager
|
Cumulative
Chance %
|
|
7
|
7 |
4.7 |
1 |
4.7
|
|
8
|
7
|
4.3
|
2
|
9.0
|
|
9
|
7
|
4.1
|
3
|
13.1
|
|
1
|
7
|
3.9
|
4
|
17.0
|
|
3
|
7
|
3.9
|
5
|
20.9
|
|
4
|
7
|
3.9
|
6
|
24.8
|
|
0
|
7
|
3.6
|
7
|
28.3
|
|
7
|
4 |
3.1 |
8 |
31.4 |
|
7
|
0 |
3.0 |
9 |
34.4 |
|
8
|
4 |
2.8 |
10 |
37.2 |
|
8
|
0 |
2.7 |
11 |
39.9 |
| 9 |
4 |
2.7 |
12 |
42.6 |
| 1 |
4 |
2.6 |
13 |
45.2 |
| 3 |
4 |
2.6 |
14 |
47.8 |
| 4 |
4 |
2.6 |
15 |
50.4 |
| 9 |
0 |
2.6 |
16 |
53.0 |
| 1 |
0 |
2.5 |
17 |
55.5 |
| 4 |
0 |
2.5 |
18 |
58.0 |
| 3 |
0 |
2.4 |
19 |
60.4 |
| 0 |
4 |
2.4 |
20 |
62.7 |
| 0 |
0 |
2.3 |
21 |
64.9 |
| 5 |
7 |
1.3 |
22 |
66.2 |
| 6 |
7 |
1.3 |
23 |
67.5 |
| 7 |
3 |
1.3 |
24 |
68.8 |
| 2 |
7 |
1.2 |
25 |
70.0 |
| 7 |
1 |
1.1 |
26 |
71.1 |
| 8 |
3 |
1.1 |
27 |
72.2 |
| 9 |
3 |
1.1 |
28 |
73.3 |
The payoff matrix for the football
pool may now be marked
to show the Order of Preference for each of
your wagers. Inasmuch
as this exercise applies the solution to The Next
Superbowl puzzle retrospectively,
all 36 past Superbowls
are already superimposed...
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
0
|
21 |
17 |
|
19 |
18 |
|
|
9 |
11 |
16 |
|
1
|
|
|
|
|
|
|
|
26 |
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
3
|
|
|
|
|
|
|
|
24 |
27 |
28 |
|
4
|
20 |
13 |
|
14 |
15 |
|
|
8 |
10 |
12 |
|
5
|
|
|
|
|
|
|
|
|
|
|
|
6
|
|
|
|
|
|
|
|
|
|
|
|
7
|
7 |
4 |
25 |
5 |
6 |
22 |
23 |
1 |
2 |
3 |
|
8
|
|
|
|
|
|
|
|
|
|
|
|
9
|
|
|
|
|
|
|
|
|
|
|
A few observations about the performance
of our tweaked model...
-
By picking a higher value for
Assumption #6 (maximum total
scores), your selections would have paid off up to
14 times. That's
merely one more than the 13 times we got using the
lower SWAG -- and it
would have required investing in at least 25 squares
per game, instead
of 22. Exclamatory punctuation is almost
unavoidable.
-
Using our initial Assumption #6, we
missed all five
winning combinations that were
duplicated plus the one combination
that appeared in the final scores of three Superbowls.
The
higher total in Assumption #6 snagged three of
them, including that triple
(4-to-7).
-
The most recent
Superbowl (XXXVI) ended
with a score of 20-to-17 (0-to-7
in
the least significant digit department), and you
would have won -- this
time if you had purchased at least 7 out of your
28 preferred squares (compared
to 14 out of 22 with the lower SWAG).
 f
you have read all the way down to here, you must find
yourself irresistibly
tempted to sponsor your own football pool for friends
and colleagues prior
to the next Superbowl. You will surely mark 28
squares as not available
for purchase, keeping them all for yourself. f
you have read all the way down to here, you must find
yourself irresistibly
tempted to sponsor your own football pool for friends
and colleagues prior
to the next Superbowl. You will surely mark 28
squares as not available
for purchase, keeping them all for yourself.
On the Monday after Superbowl Sunday,
having spent the
previous day on your couch getting advertised to, you
will take $72 to
the bank. Either that or you must pony up $28
out of your lunch money
to pay off the winner.
What, do you suppose, is the
likelihood of that?
Definition
of a Model
Donella H. and Dennis L.
Meadows, in their landmark
1972 book, The Limits to Growth: Report for the
Club of Rome's Project
on the Predicament of Mankind, defined a model
as an ordered
set of assumptions. Their modeling of the
future continues to
be both acclaimed and vilified.
Over the years, few critics have
understood that the idea
is to challenge the assumptions underlying an analysis
not the results.
Now, it is a long way from The
Next Superbowl
puzzle
to "the Predicament of Mankind." Or is it? {Return}
The Law
of Averages? Which Law!
An average is merely one estimate of
"central tendency."
So is a median. Deviations often matter
more. An average of
22.5 is not a particularly attractive representation
of all the values
between 15 and 30. Distributions can be weird,
too. Oh right, and fractional results are often
unusable: The
average of two 7s and one 3 is 5.67,
for which our payoff
matrix offers no square.
You can assign values in some arbitrary
order (7,7,3,7,7,3...),
but it's not cool to project events as occuring in any
particular pattern
when no particular pattern can be justified. A
randomizing element
is often used with good effect. In the solution
to Randomly
Wrong you will find a Monte Carlo style of
model, in which random numbers
operate on a key variable. That's what we shall do
here. {Return}
Spreadsheet
Model for Solving the Next Superbowl Puzzle
Sophisticated solvers might want to
play with the model
that produced the results reported here. If so,
send an e-mail request
to puzzles@niquette.com.
{Return}
History
of the Superbowl
SUPER
BOWL |
DATE |
CONFERENCE
WINNER
CONFERENCE LOSER |
SCORE |
HEAD
COACH |
SITE |
| I |
1/15/67 |
Green
Bay, NFL
Kansas
City, AFL |
35
10 |
Vince
Lombardi Hank
Stram |
Los
Angeles, CA |
| II |
1/14/68 |
Green
Bay, NFL
Oakland,
AFL |
33
14 |
Vince
Lombardi John Rauch |
Miami,
FL |
| III |
1/12/69 |
New
York Jets, AFL
Baltimore,
NFL |
16
7 |
Weeb
Ewbank Don Shula |
Miami,
FL |
| IV |
1/11/70 |
Kansas
City,
AFL
Minnesota,
NFL |
23
7 |
Hank
Stram
Bud
Grant |
New
Orleans, LA |
| V |
1/17/71 |
Baltimore,
AFC
Dallas,
NFC |
16
13 |
Don
McCafferty Tom Landry |
Miami,
FL |
| VI |
1/16/72 |
Dallas,
NFC
Miami,
AFC |
24
3 |
Tom
Landry
Don
Shula |
New
Orleans, LA |
| VII |
1/14/73 |
Miami,
AFC
Washington,
NFC |
14
7 |
Don
Shula
George
Allen |
Los
Angeles, CA |
| VIII |
1/13/74 |
Miami,
AFC
Minnesota,
NFC |
24
7 |
Don
Shula
Bud
Grant |
Houston,
TX |
| IX |
1/12/75 |
Pittsburgh,
AFC
Minnesota,
NFC |
16
6 |
Chuck
Noll
Bud
Grant |
New
Orleans, LA |
| X |
1/18/76 |
Pittsburgh,
AFC
Dallas,
NFC |
21
17 |
Chuck
Noll
Tom
Landry |
Miami,
FL |
| XI |
1/9/77 |
Oakland,
AFC
Minnesota,
NFC |
32
14 |
John
Madden
Bud
Grant |
Pasadena,
CA |
| XII |
1/15/78 |
Dallas,
NFC
Denver,
AFC |
27
10 |
Tom
Landry
Red
Miller |
New
Orleans, LA |
| XIII |
1/21/79 |
Pittsburgh,
AFC
Dallas,
NFC |
35
31 |
Chuck
Noll
Tom
Landry |
Miami,
FL |
| XIV |
1/20/80 |
Pittsburgh,
AFC
L.A.
Rams, NFC |
31
19 |
Chuck
Noll
Ray
Malavasi |
Pasadena,
CA |
| XV |
1/25/81 |
Oakland,
AFC
Philadelphia,
NFC |
27
10 |
Tom
Flores
Dick
Vermeil |
New
Orleans, LA |
| XVI |
1/24/82 |
San
Francisco, NFC
Cincinnati,
AFC |
26
21 |
Bill
Walsh
Forrest
Gregg |
Pontiac,
MI |
| XVII |
1/30/83 |
Washington,
NFC
Miami,
AFC |
27
17 |
Joe
Gibbs
Don
Shula |
Pasadena,
CA |
| XVIII |
1/22/84 |
L.A.
Raiders, AFC
Washington,
NFC |
38
9 |
Tom
Flores
Joe
Gibbs |
Tampa,
FL |
| XIX |
1/20/85 |
San
Francisco, NFC
Miami,
AFC |
38
16 |
Bill
Walsh
Don
Shula |
Stanford,
CA |
| XX |
1/26/86 |
Chicago,
NFC
New
England, AFC |
46
10 |
Mike
Ditka
Raymond
Berry |
New
Orleans, LA |
| XXI |
1/25/87 |
N.Y.
Giants, NFC
Denver,
AFC |
39
20 |
Bill
Parcells
Dan
Reeves |
Pasadena,
CA |
| XXII |
1/31/88 |
Washington,
NFC
Denver,
AFC |
42
10 |
Joe
Gibbs
Dan
Reeves |
San
Diego, CA |
| XXIII |
1/22/89 |
San
Francisco, NFC
Cincinnati,
AFC |
20
16 |
Bill
Walsh
Sam
Wyche |
Miami,
FL |
| XXIV |
1/28/90 |
San
Francisco, NFC
Denver,
AFC |
55
10 |
George
Seifert Dan Reeves |
New
Orleans, LA |
| XXV |
1/27/91 |
N.Y.
Giants, NFC
Buffalo,
AFC |
20
19 |
Bill
Parcells
Marv
Levy |
Tampa,
FL |
| XXVI |
1/26/92 |
Washington,
NFC
Buffalo,
AFC |
37
24 |
Joe
Gibbs
Marv
Levy |
Minneapolis,
MN |
| XXVII |
1/31/93 |
Dallas,
NFC
Buffalo,
AFC |
52
17 |
Jimmy
Johnson
Marv Levy |
Pasadena,
CA |
| XXVIII |
1/30/94 |
Dallas,
NFC
Buffalo,
AFC |
30
13 |
Jimmy
Johnson
Marv Levy |
Atlanta,
GA |
| XXIX |
1/29/95 |
San
Francisco, NFC
San
Diego, AFC |
49
26 |
George
Seifert Bobby Ross |
Miami,
FL |
| XXX |
1/28/96 |
Dallas,
NFC
Pittsburgh,
AFC |
27
17 |
Barry
Switzer
Bill
Cowher |
Tempe,
AZ |
| XXXI |
1/26/97 |
Green Bay,
NFC
New
England, AFC |
35
21 |
Mike Holmgren
Bill
Parcells |
New Orleans,
LA |
| XXXII |
1/25/98 |
Denver,
AFC
Green
Bay, NFC |
31
24 |
Mike
Shanahan Mike Holmgren |
San
Diego, CA |
| XXXIII |
1/31/99 |
Denver, AFC
Atlanta,
NFC |
34
19 |
Mike Shanahan
Dan
Reeves |
Miami, FL |
| XXXIV |
1/30/00 |
St. Louis, NFC
Tennessee,
AFC |
23
16 |
Dick
Vermeil
Jeff Fisher |
Atlanta,
GA |
| XXXV |
1/28/01 |
Baltimore,
AFC
N.Y. Giants,
NFC |
34
7 |
Brian
Billick
Jim Fassel |
Tampa,
FL |
| XXXVI |
2/03/02 |
New England,
AFC St. Louis,
NFC |
20
17 |
Bill
Belichick
Mike Martz |
New
Orleans, LA |
{Return}
Epilog
Among the messages commenting on The
Next Superbowl
puzzle was one I received just in time
for the
2003 contest, which included a query that has given me
an idea for applying
the solution to conventional sports pools.
| Dear Paul,
All of the football pools I have participated
in have assigned the row
and column values randomly. At the end
of each quarter of play, winnings
are paid.
How does this affect the values of the
squares, and what combination
should I try to purchase from my coworkers?
Thanks,
Bill
|
| Dear Bill,
Yes, it is that time of year again.
Here are my comments about
your present wagering situation...
-
Unlike a conventional pool, the puzzle
itself called for making choices
of squares from pre-assigned column and row
headings, attributable to the
expected winning and losing teams. You
have already had random decisions
made for you.
-
There were two models developed: the first
is based on ten explicit assumptions,
the second was "tweaked" by historical
information. Both models apply
only to final scores, so those quarterly
payoffs are really out of scope,
so to speak.
-
Intermediate results would appear to sweeten
your wagering deal (with more
than one opportunity to win a non-zero
amount) while diluting the payoff
for each outcome from the total pool.
-
The best use of the model arises in a
non-randomly assigned pool; accordingly,
a dandy guide for purchasing squares -- with
known payoffs -- from your
coworkers can be found in the rankings
tabulated in the "tweaked" model
(biased, presumably, by expert projections
of the favored football conference).
Wishing you good luck, I am merely,...
Paul Niquette
P.S. Should you feel an overwhelming desire
to share your winnings,
you will find my address here.
|
 he
expected
value of each square can be estimated from the
"tweaked" model by converting
those "Joint Chance" percentages into dollars.
Accordingly, if you
do not own them already (as a result of purchasing
random assignments),
those first three choices (7-7,
8-7,
9-7)
appear to be worth more than $4.00 each. he
expected
value of each square can be estimated from the
"tweaked" model by converting
those "Joint Chance" percentages into dollars.
Accordingly, if you
do not own them already (as a result of purchasing
random assignments),
those first three choices (7-7,
8-7,
9-7)
appear to be worth more than $4.00 each.
Your coworkers, having not studied the
solution to The
Next Superbowl
puzzle, ought to be happy to accept an
offer
of, say, $2.00 for each of them, which means they have
doubled their money
before the opening kick-off. Meanwhile, for a
total investment of
only six bucks, you're looking at better than a 13%
chance to win a C-note.
Remember, a corporate
executive often has no
other choice but to believe his or her
business model when making
decisions -- often huge, critical decisions -- about
the future.
If you really believe the
"tweaked" model, then you
would go around offering $2.00 to your coworkers for the
first nine choices.
That might get you as much as a 34% chance at $100, for
only $18 put at
risk.
There is a fallacy in this reasoning,
of course.
You still have to win based on the gridiron results,
and there's a 2/3rds
chance that you won't. Meanwhile, nine of your
coworkers are no longer
at risk, having already pocketed their winnings. They
have renounced their
interest in "The
Gambler's
Playoff." Thus, those who sell you their
squares won't
experience the same excitement while watching the game
as you will.
Finally, if you do lose, one of your
coworkers will have
won that $100, and he or she only put up a buck.
Which of you will
have had more fun on Superbowl Sunday?
|